𝗗𝗼 𝗜 𝗸𝗻𝗼𝘄 𝗺𝘆 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲?
Part 2
With the goal of looking at some implementation details of various DBMS, continuing from my last post, I want to share some details of MySQL's internals. Again, the major reference has been Jeremy Cole's blogs and MySQL Docs
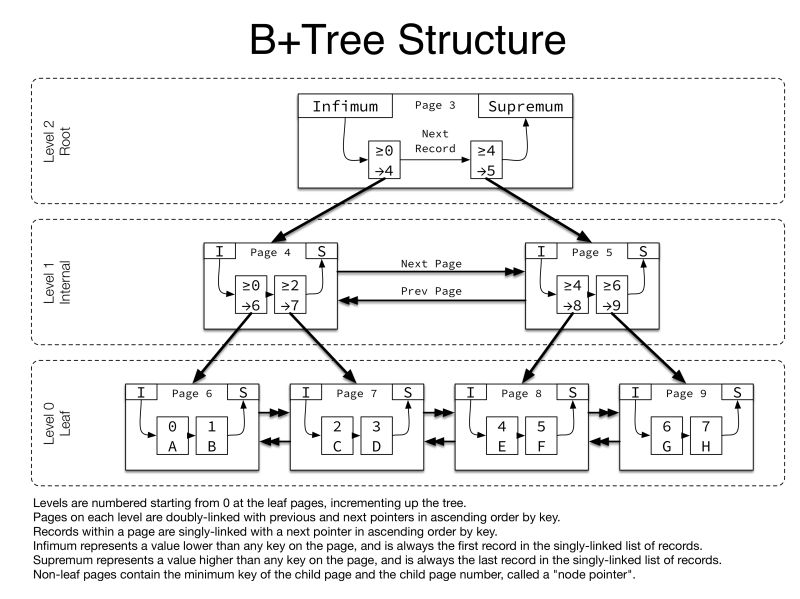
Mysql index is implemented as a B+ tree.
(In the dev docs, the use of the term B-tree is intended as a reference to the general class of index design.)
The B + tree lets the index quickly find a specific value, a set of values, or a range of values, corresponding to operators such as =, >, ≤, BETWEEN, IN, and so on. The index also can be used for LIKE comparisons if the argument to LIKE is a constant string that does not start with a wildcard character.
Any index that does not span all AND levels in the WHERE clause is not used to optimize the query. In other words, to be able to use an index, a prefix of the index must be used in every AND group.
The “row data” (non-PRIMARY KEY fields) are stored in the PRIMARY KEY index structure, which is also called the “clustered key”. This index structure is keyed on the PRIMARY KEY fields, and the row data is the value attached to that key (as well as some extra fields for MVCC). So the table’s data is basically stored in the leaf nodes of the index. (image 2)
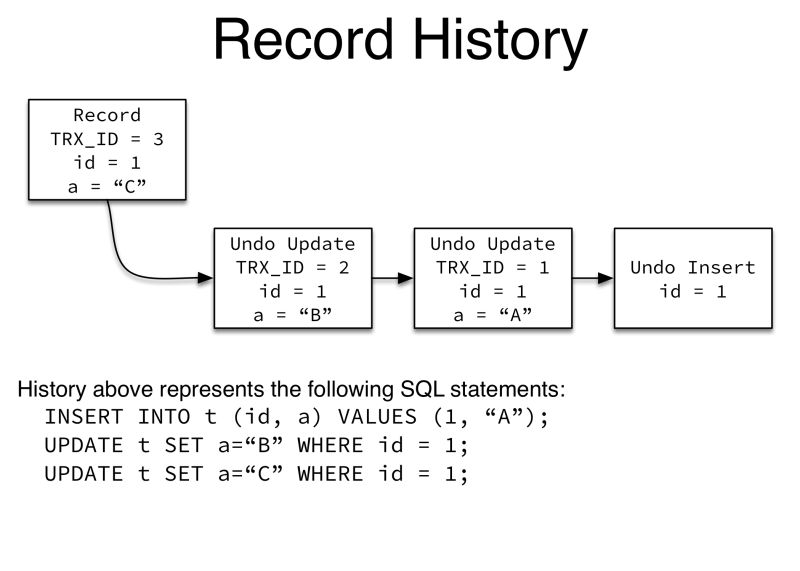
InnoDB implements multi-version concurrency control (MVCC), meaning that different users will see different versions of the data they are interacting with. Undo logging and InnoDB’s “history” system are the mechanisms that underlie its implementation of MVCC. (image 3)
Benefits of MVCC?
Improved read access performance
Diminished need for database locks
Fewer database access contention issues
Continued record isolation for write operations
Reduced number of database deadlocks
Some things that can affect performance, so you should keep in mind:
Transactions always operate on the “live” data - there are no private copies
Deleting isn’t really deleting, just marks a record as deleted
In the background, InnoDB runs a continuous “purge” process which is responsible for two things:
Actually deleting delete-marked records, if the record hasn’t been re-inserted.
Freeing undo log pages and unlinking them from the global history list to make them available for re-use.
Given these points, because a long-running transaction has an old (potentially very old) read view, purging of undo logs (history) for the entire system will be stalled until the transaction completes.
Also, after a huge update/insert/delete in your DB, you might want to run this command : OPTIMIZE Table
For InnoDB tables, OPTIMIZE TABLE rebuilds the table to update index statistics and free unused space in the clustered index.
Say, if you have deleted a lot of records in a table, and there is no running process using your database, this command can rebuild the index for that table and save space.